



 Like
Like Share
Share
 Report
Report1. Overview
Customer Insights Data (CI-D) is a Customer Data Platform (CDP) and as such, like for any data project, one of the most critical parts when implementing the solution is data integration: connection, preparation and ingestion from the different source systems.
What would be considered a typical ETL (Extract, Transform and Load) or ELT (Extract, Load and Transform) task in the context of generic data project.
Data integration will probably be the most resource intensive task, more often than not representing from 33% and up of 50% of the overall effort, of a Customer Insights Data implementation, while also being foundational to everything you’ll define in CI-D after this, so if there is one piece not to be overlooked it is this one.
The goal of this blog post series is to describe the inbound data batch integration patterns (we will use the term "integration patterns" for short from now on) that are possible for CI-D - with their respective advantages, limitations or constraints - to allow the most informed decision possible to be made before going into the actual implementation.
In this first introductory blog post, we will cover the following topics:
- Describe the CI-D Data processing architecture
- Give a first high level overview of each available integration pattern
- Provide an integration pattern selection matrix
Forthcoming blog posts will get in depth on each individual ingestion pattern described in this blog post and will each cover:
- Introduction to the Integration pattern
- Decision factors for leveraging this pattern
- Example of decisions factors walkthrough
- Reference and sample architectures
- Pre-Requisites and Capabilities
|
We will update this blog post frequently to inform you of upcoming new patterns or modifications to existing patterns, along with their impacts on the pattern selection matrix.
|
2. Customer Insights Data - Data Processing Architecture
Customer Insights Data is a Customer Data Platform, which is a SaaS business solution whose main purpose is to allow to:
- Integrate disjointed and siloed customer data (e.g. contacts and their activities) from various source systems.
- Unify it
- Optionally Enrich it
- Augment it with the help of AI
- “Pre-activate” it through measures and segments
- Export it to downstream activation system(s).
To allow to achieve this at large scale, behind the scene, CI-D is “built on the back of giants”, relying on Azure services, Dataverse and the Power Platform .
CI-D follows “Elastic Cloud Big Data” principles for data processing, with two principal de-collocated components that can be scaled independently: a Spark processing engine (‘Azure Synapse Analytics) and a Data Lake Storage.
2.1 CI-D Inbound Data integration experience
The CI-D data integration experience let you choose between six different (yet not mutually exclusive) integration patterns.
This Blog post series will not cover the “Data Library for Customer Insights – Data” Data Source which aims at providing demo data sets for multiple industries.
2.2 CI-D Data Processing Logical Architecture
The following logical architecture diagram intends to give a comprehensive view of the CI-D Data Processing Logical architecture and uses some key concepts, such as "Source Lake" and "Storage Lake", that will be explained in the subsequent chapters of this blog post.
In the forthcoming Blog posts related to the “Ingestion Pattern” series, we’ll provide you with a dedicated logical architecture schema for each integration pattern.
2.2.1 Data Lake Storage (Storage Lake)
The Data Lake storage is a highly scalable storage where CI-D processes output results will be stored. This storage is referred to as “Storage Lake” in this document.
CI-D Storage Lake is provided:
- Either as an integral part of Customer Insights Data, managed by Customer Insights Data, and included in the licensing, what we call CIDS for “Customer Insights Data Storage”. In this case, the storage relies on a Dataverse Managed Data Lake
- Or as an Azure Data Lake Storage Gen2 provided by the customers, if they prefer this option, what we call BYOSA for “Bring Your Own Storage”
| The choice of Storage Lake provisioning is made during Customer Insights Data instance creation, it cannot be changed thereafter without deleting the instance and creating a new one, but has no adherence whatsoever to what can be used as a data integration pattern. |
2.2.2 Source Lake
When a CI-D processes require to work on Source System data, they will need to get it from the Source Lake. Once data is available from the source lake, it can be consumed by CI-D Spark processing engine.
This Source Lake can be provisioned and fed in different manners:
These are the integration patterns that CI-D supports when this blog post was written. Please check this link for the most recent updates.
This Source Lake can be provisioned and fed in different manners:
- Import and Transform (Power Query): the Power Query low-code no-code ETL experience, exposed through CI-D’s user interface, will support transforming the data from your source systems and ingesting the transformed data in the Source Lake. In this case, the Source Lake is managed by your Dataverse environment as a Dataverse Managed Data Lake.
- Microsoft Power Query being an import type pattern, this pattern induces data movement and requires Source Lake storage capacity.
- Attached Lake: refers to 3 integration patterns: Azure Data Lake Common Data Model Tables, Azure Data Lake Delta Tables and Azure Synapse Analytics.
- Leveraging those patterns, CI-D will consume data made available by the customer in an Azure Data Lake Gen2 Storage Account. In this case, the Source Lake is provisioned and managed by the Customer’s IT department in its Azure tenant and can be fed by many integration solutions (e.g. Azure Data Factory , market IPAAS solutions) and leverage multiple integration patterns such as API, ESB, ETL, MFT …outside and before Customer Insights Data starts reading the data from it.
- “Microsoft Dataverse”: This integration pattern replicates a Dataverse environment’s selected tables to a Dataverse managed Data Lake which becomes the Source Lake of CI-D.
| The different patterns are not mutually exclusives, meaning that they can co-exist in a same CI-D instance, even though it is recommended when possible to reduce the number of leveraged patterns as it will simplify implementation, evolutions and maintenance by reducing the number of different skillsets required to manage data integration for CI-D. |
3. High level overview of each available integration patterns
3.1 CI-D Integration Patterns status
These are the integration patterns that CI-D supports when this blog post was written. Please check this link for the most recent updates.
| Pattern Type | Status | Incremental ingestion | Firewalled cloud sources support | Comments |
| Microsoft Power Query | Generally Available |
No | Yes (through Data Gateway) |
Leverages Power Platform DataFlows (analytical flows) capability of Dataverse and the connectors available within it for Ci-D. |
| Azure Data Lake - Common Data Model Tables | Generally Available |
Yes | Yes (CI UI allows to generate private endpoints toward ADLS Gen2) |
|
| Azure Data Lake - Delta Tables | Generally Available |
Yes | Yes (CI-D UI allows to generate private endpoints toward ADLS Gen2) |
|
| Microsoft Dataverse | Generally Available |
No | Not Available | Significant improvements to the Microsoft Dataverse pattern are planned. Learn more through this link. |
| Azure Synapse Analytics | Public Preview | No | No | Only Spark Pools are supported. No planned General Availability Date |
Some additional details about the above table:
As part of this blog article series, we’re proposing 5 decision factors to be detailed and assessed when evaluating integration patterns.
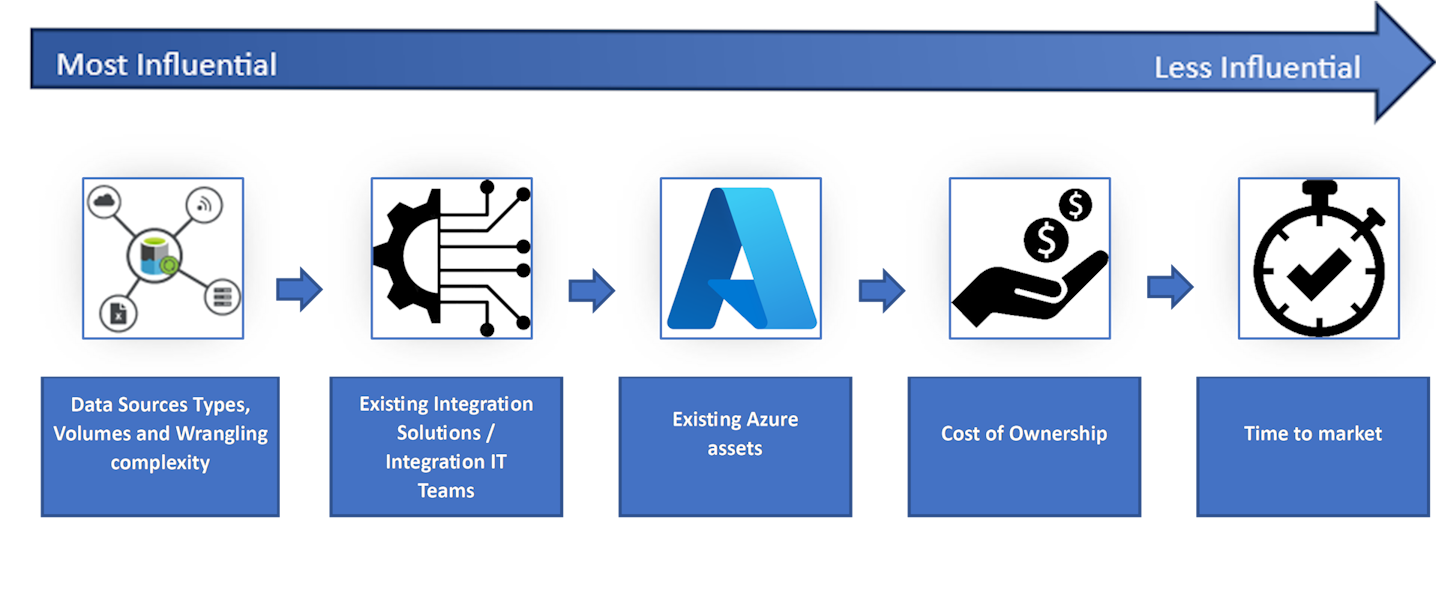
In the forthcoming Blog posts related to the “Inbound Batch Data Integration Patterns” Serie, we’ll provide you with a detailed walkthrough of the Selection Matrix for each integration pattern.
- The “Incremental ingestion” column indicates if the integration pattern supports processing incremental data refresh versus redoing a full data refresh each time.
- Please note that CI-D is not a data persistence layer and does not aim to serve as a data offloading facility for your source system data.
- Required source system data must stay available from the source, irrespective of “Incremental Ingestion” use. This is important to support cases where a full data reload may be required. More details will be provided in the forthcoming blog posts related to each integration pattern.
- The “Firewalled cloud sources support” column indicates if the integration pattern would support connecting and ingesting from Azure Cloud Data Source(s) which are not exposed to Public Networks. Please note that only “Microsoft Power Query” will support direct connection to “OnPrem” and non-Azure Data sources through an On-Premises data gateway and through supported connectors.
| Preview features aren't meant for production use and may have restricted functionality. These features are available before an official release so that customers can get early access and provide feedback |
4. Integration Patterns Selection Matrix
4.1 Decision factors description
As part of this blog article series, we’re proposing 5 decision factors to be detailed and assessed when evaluating integration patterns.
Those decision factors are presented by descending order of priorities for the decision process.
| Data Sources Types, Volumes and Wrangling Complexity | Having a clear picture of available Data Sources to be ingested in CI-D is key to make an informed decision on the integration pattern(s) selection. Data Sources should be evaluated on:
|
| Existing Integration Solutions / Integration IT Teams | Overall Solution architecture should benefit from existing Customer’s Integration solutions and associated Integration teams expertise, when they exist. Thus ensuring that CI-D implementation can rely on proven industrialization and support processes. Lack of existing solutions or supporting IT Teams skillset may be a blocker or induce implementation delays on some integration patterns. |
| Existing Azure assets | Many customers have already invested in Azure solutions and it’s not uncommon that solutions like Synapse, ADLS Gen2, ADF or Dynamics 365 Solutions (relying on Dataverse) are already available inside of the Customer ecosystem. In this situation, synergies should be seek on leveraging those services (and associated Customer IT Teams) to support the integration patterns. |
| Cost of Ownership | Each integration pattern will induce a different cost of ownership for the customer. This cost is typically related to the operating costs of solutions supporting the envisioned ingestion patterns and to the expected number of Data Sources and data pipelines to be operated as to ensure customer data is prepared for CI-D Ingestion. |
| Time to market | Some integration patterns would require having some dependencies on Data Integration teams which needs to be taken into account in the implementation plan. In addition, a customer may realize that some additional Data preparation challenges may arise from his particular context and would require additional work items to achieve a consistent CI-D Solution architecture |
4.2 Selection Matrix
The following table gives you an initial overview of how the different integration patterns relate to the Decision factors that were described earlier.
In the forthcoming Blog posts related to the “Inbound Batch Data Integration Patterns” Serie, we’ll provide you with a detailed walkthrough of the Selection Matrix for each integration pattern.
| Decision Factors / Integration patterns | Data source type, Volume and Wrangling complexity | Existing Integration Solution, project team skillset and access to IT Teams | Existing Azure Assets | Cost of Ownership | Time To Market |
| Microsoft Power Query | *Up to 5 million records with low to medium wrangling complexity. | Low to Medium Skilled with Azure Data Gateway depending on source location and M-Query |
Low No requirement for additional Azure assets |
Low | Low Quick time to market and hence good approach for POCs |
| Azure Data Lake - Common Data Model Tables | Complex wrangling requirements OR Medium to large data volume |
Medium to High Knowledge of ADLS Gen2 is required. ETLs like ADF, Synapse for data prep/wrangling |
Medium to High Leverage an existing enterprise data platform (ADLS Gen2) with some of your Organisation’s data estate |
Medium | Low to Medium Availability of data AND Availability of team to prepare additional data |
| Microsoft Dataverse | **No wrangling requirements | Low Sync between DV entities and DL is transparent to end users |
Low | Low | Low |
| Azure Data Lake - Delta Tables |
Complex wrangling requirements OR Medium to large data volume |
Medium to High Skillset for Azure Databricks or Azure Synapse Analytics |
Medium to High Leverage an existing LakeHouse or Enterprise Data Platform with some of your Organisation’s data estate |
Medium | Low to Medium Availability of data AND Availability of team to prepare additional data |
| Azure Synapse Analytics (preview) |
Complex wrangling requirements OR Medium to large data volume |
Medium to High Skillset for Azure Synapse Analytics – Spark pools |
Medium to High Leverage existing enterprise Data Warehousing (Azure Synapse Analytics – Spark pools and synapse workspace) with some of your Organisation’s data estate |
Medium | Low to Medium Availability of data AND Availability of team to prepare additional data |
* Power Query’s ability to perform is dependent on many factors including connector used, data volumes, wrangling complexity… and hence must be thoroughly evaluated if it is a valid option before selecting this ingestion pattern
** Ensure that the data in source entities doesn’t contain newline characters/carriage returns specially found in composite address fields.
** Ensure that the data in source entities doesn’t contain newline characters/carriage returns specially found in composite address fields.
*This post is locked for comments