



 21
21 Like
Like Share
Share
 Report
Report
Wassup Guyz?
Today will talk about Linking Azure Cosmos DB to Azure Synapse Analytics, and then dealing with its migrated data.
As we all know, Azure Cosmos Db had been in the market for quiet a time now. Azure Cosmos DB is a globally distributed, multi-model database service offered by Microsoft. It is designed to provide high availability, scalability, and low-latency access to data for modern applications. It is a fully managed NoSQL and relational database for modern app development, whereby you can store the humongous volume of dataset, allowing them to be easily replicated across regions/locations, in a most effective way.
Essentially in a Cosmos DB, we create a Database (we call it a TodoList) and inside it the we keep Tables (called as Items), into which we can keep our records. And as you have rightly guessed, the reccords are stored in form of JSON structures, and you have provision to query the records and even create triggers/stored procs on them.
Creating a Cosmos DB is very straight forward:
Reach out to https://portal.azure.com and search for Cosmos DB:

In the screen that opens, choose Azure NOSQL >> fill out the form as follows:

Click Review + Create to create/deploy a Cosmos DB account.
It will take a while to create and make your DB ready. As stated above here are the Todolist and Item, which got created:


I have prepared a JSOn file beforehand to feed it into the Cosmos DB:


It's showing the records in JSON format. Alternately you can directly see all the records, by clicking on items themselves:
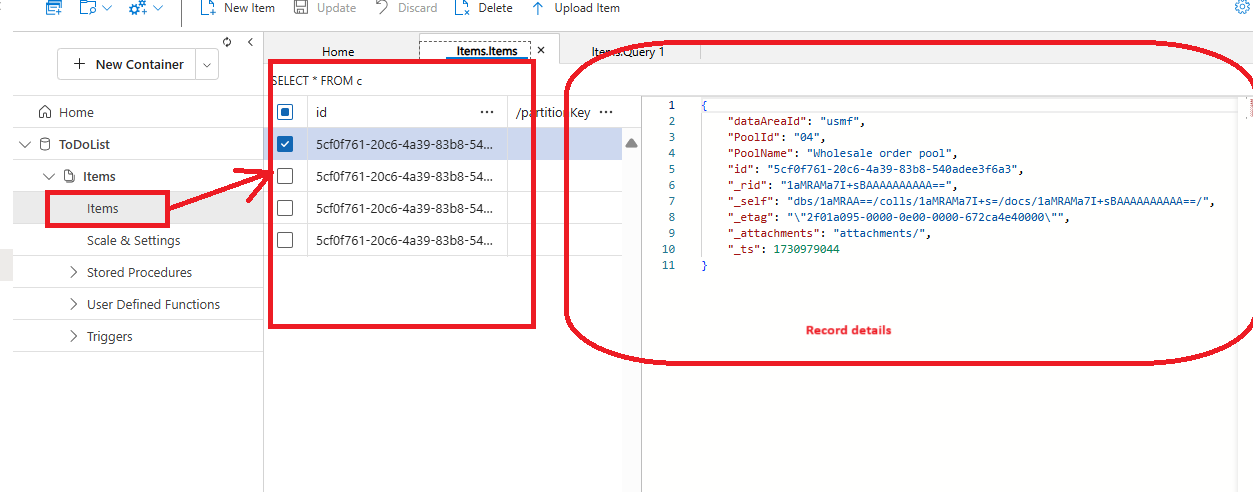
Under Integration, search for Azure Synapse Link:

One done, you would get to see that account has been enabled successfully:

You need to select Containers which you need to enable: as I did in the above figure. This would take a while to activate the containers.
Once done, click on Next:

Select the Subscription, Azure Synapse Workspace (alterantely you can create a New one) and the database foe which you need to link with Azure Synapse.
Click Next to continue.
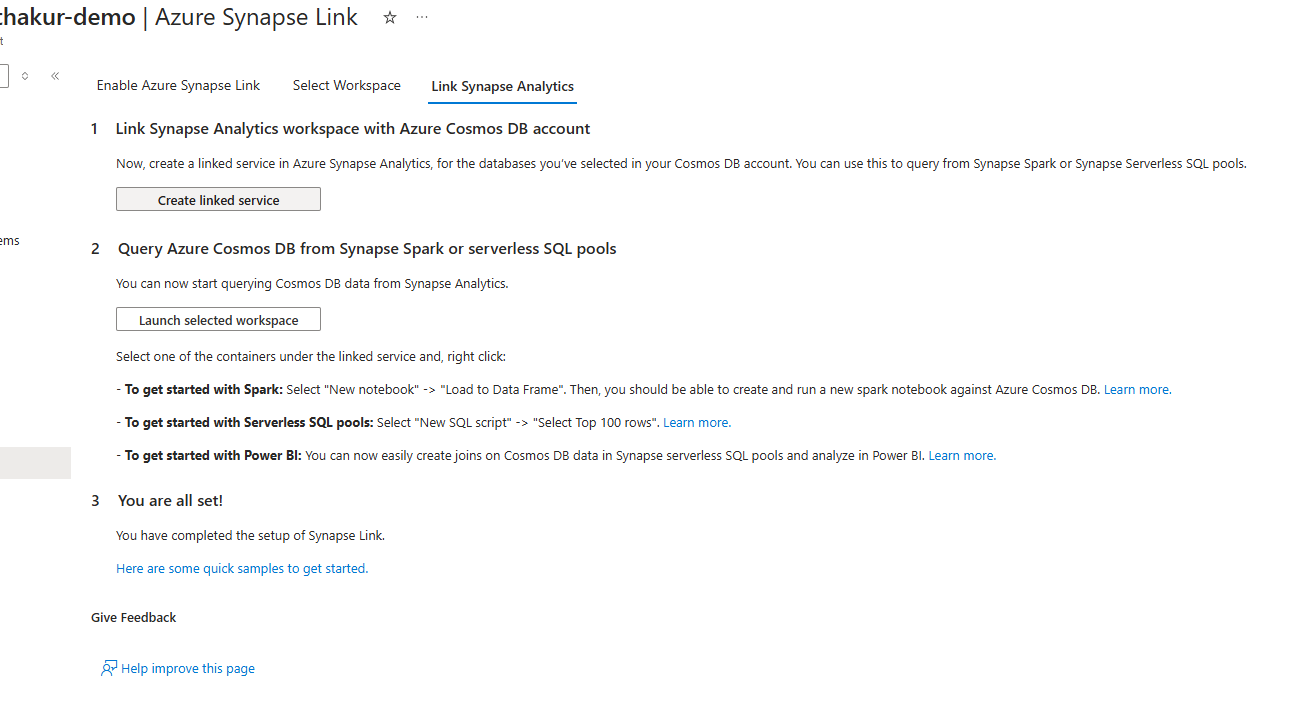
Click on Create Linked Service: this will create a Linked service in the Azure syanpse worksapce. And finally you are all set to go. Click on Launch selected workspace >> it will open the workspace and show the Linked Service thus created:

Now we can explore the data thus created/migrated from Cosmos DB to here. For that you need to create a Spark Pool; you can select an existing pool or create a new one, by clicking on manage pool.

For this, do the correct calculation of Node size * no. of vCores:


Its a very simple Python code that selects all the columns from Items and shows it in a Dataframe:

Alternately I can select only specific fields in my query and display it:
import pandas as pd
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService", "CosmosDBLSToDoList")\
.option("spark.cosmos.container", "Items")\
.load()
dfSubSet = df[['dataAreaId', 'PoolId', 'PoolName']]
display(dfSubSet.limit(10))
Where I am specifying the columns like PoolId, PoolName, etc. and storing the result in a dataframe subset. But for that, you need to import Pandas, as shown in the code.
Which will give me:
Cool, nah?
Cool, nah?
Yes -- that's it for today, I will soon be coming back with another topic on data engineering. Till then, take care and Namaste, as always 💓💓💓
*This post is locked for comments