



How can programmers understand Machine Learning paradigm
 667
667
 Like
Like Share
Share
 Report
ReportIntroduction: what´s the new stuff?
This summer I have been reading a lot of books about this subject, and I wanted to write an article for developers about my first question before reading these books: what machine learning really is? In this post I will overlook some concepts that were in every machine learning book (supervised, no supervised, data refinery, test data, clustering, overfitting, underfitting), to focus in really machine learning is and how to explain it to traditional programmers. In the text you will notice I am not a data science expert, and I preferred simplicity over accuracy. So, if you find errors, send me some feedback if you like. I haven´t did any hands-on yet. Theory is big enough to take all my time.
Explicit vs implicit: that´s the question. Machine learning as programing paradigm
When a programmer needs to evaluate a condition, we must have explicit rules:
- If customer credit is less than customer debt, warn the user this is a risky commercial operation.
- If item availability if less than item needs I must open avail item information panel.
- If posting date is empty I must raise an error on document posting.
We know explicit rules and apply them in our code.
But we can have a problem, when the rules are not so clear or these rules aren´t easy to code.
Let´s think about a classic artificial intelligence problem: MNIST, a handwritten digit images database that is used as “hello world” of Artificial Intelligence. In this case we pretend from an image file of a number find out number value:
This picture Is nine number. Very easy for a human but imagine yourself taking a handwritten digit photo and coding in your program: “ If the image has a circle with and have a curve line bellow, number equals to nine”. But you can´t do this: some things that are easy for humans, are tough for a machine, it doesn’t know what a circle is in an image, and probably if it knows it would expect a perfect circle instead a handwritten circle.
Other times the polices aren´t so clear or we don´t want to make previous assumptions , we want to make a root cause analysis of an output. Let´s take this example, a program to detect safe drivers for a car insurance. We can take the assume that young males are a bit more careless drivers and put this instruction: “if customer is young and male then raise a warn of potential unsafe driver”.
But what happens if we are not sure about these criteria or we want to take more parameters to make the prediction?
Then we can solve this problem with machine learning. We don´t give to the machine explicit rules, we give the machine a set of data and through a process called training, machine gets a model to predict the output with new input values.
Note: we are going to use the word prediction in a very wide sense. For a human a prediction is: How much will I sell next year? Will this person be a bad driver and will his car insurance be a bad business for me? For humans, predictions are only about future. But for a machine a prediction could be answer a question like: Is this image a handwritten number nine ? Is this the photograph of a dog?
The starting point: Data features and labels.
The beginning of machine learning Is feed the machine with data. The input of the “driver assurance” model could be a Csv file with a previous history of past assurances, with the next columns:
- Age.
- Gender, male or female.
- Race.
- Annual incomes.
- Level of education.
- Good driver (yes/no). We have checked this field if the driver has given many problems and costs to insurance company.
The goal is to make a system that predict column “Good Driver” in new inputs. So, we have two kind of columns:
- Features, AKA independent columns. These columns are the input of the system (Age, Education, Incomes, Race and Gender).
- Label. Is the output of the system, AKA dependent column. In our example the label is the goal of the predictor model, the “Good driver” column. We add actual and accurate values of the output to able the machine learns, comparing the actual output values with model predicted values.
There is also a lot of stuff about data, is the main and more difficult step. Create machine learning models isn´t an easy work. Takes a lot of business knowledge and a solid data-science background. This is not my case, so I suggest use existing models or use ML tools.
Data always require a lot of transformations, remove irrelevant columns, convert all the columns in numeric values, and normalize the range of the values.
Converting images in data for machine learning process.
In the case of image, before apply math algorithms, we must convert images in arrays of pixels. These arrays are called tensors. A Tensor is a multidimensional data structure, that allows calculation in complex structures. Einstein used tensors in gravity calculations for General Relativity Theory.
We have the MNIST database with a lot of examples of handwritten numbers. They are pictures of 28x28 pixels. So, we convert this in a 28x28=784 elements array to store all the pixels with integer values from 0 to 255 (color of each pixel).
The output will be an array with 10 binary elements(an element for each possible output digit from 0 to 9), so 9=[0,0,0,0,0,0,0,0,0,1], 8=[0,0,0,0,0,0,0,0,1,0], etc. In training step, we will search for a mathematical model that fits with the output, so we must input only numbers, and this way we can apply algorithms.
The conclusion: all data you could use in Machine learning must be transformed in numbers!!!!
Training machine to get a model: All about math.
Then we must give the dataset to the machine with the two column categories: features (age, gender, level of education) and label (Good Driver), with known data. Now we must make n iterations using an algorithm:
- We give the machine the labelled historical (with actual output) data for the Training.
- Machine applies algorithms to find a formula to generalize and predict the label of other new values, which output is still unknown.
How does the machine get this formula to make predictions? First we have to choose an algorithm. For a simple problem we can use a linear regression (for very simple cases, with a single input), we have this formula Output(predicted)=Bias +Feature*Weight. Machine must find values for “Bias” and “weight”. In machine learning constants that are added to the model are called “bias”. And product factors of the formula use to be called “weight” or “slope”.
For more complex problems we use another algorithm as Artificial Neural Network. We have a lot of available algorithms, decision tree, logistic regression, etc.
We have the training data and the algorithm, and the machine try to fit the formula finding the bias and factor (weight) for the formula (in linear regression) or weights and bias for neural networks.
The next question is: how does machine find these values? To answer the question, we are going to introduce the cost or loss concept. Loss is the difference at the end of the training iteration between actual output value and estimated output value, using our prediction model. To be more accurate, is the sum of all these differences.
If you are training a predictive model to get sales budget, and you have Actual sales of year 2018=30.000 and your predictive model calculate 10.000 the loss (or cost)=Predicted-Actual=-20.000. And we use the sum of all the losses of the predicted training examples to get the loss value.
Note: this is a little simplification, in machine learning is used RMSE (N is the number of rows of our training set.). I take this formula from site https://www.includehelp.com/ml-ai/root-mean-square%20error-rmse.aspx
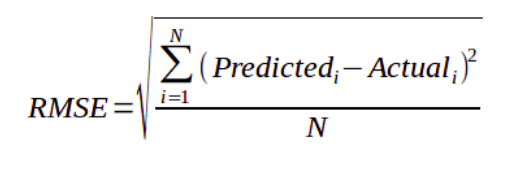
So, the core and magic of machine learning is to make iterations with all training data rows setting formula values (bias and slope or weight), and stop searching when these values make the RMSE (loss or cost) it´s minimum.
How can the iteration know which the min value of loss is? Searching the minimum could be an infinite try and error task: to avoid a non-stop iterations we can set a max number of iteration or use some mathematical tools ( we talk about they bellow in next section).
Artificial Neural Networks.
A lineal regression as shown above is the simplest algorithm you can use in Machine Learning. A linear regression is not able to implement deep learning. For complex learning we use another algorithm simulating human neural net, called Artificial Neural Network.
If we want to recognize and image, make a more complex prediction we must use a neural network:
If we are recognizing an image:
Neural Networks. How does it work?:
Sorry math again. We have these elements:
- The circles are Nodes, that simulate neurons.
- The nodes are interconnected, from a layer to next layer.
- The first layer, called input layer, receives all the values of the features training rows.
- Input layer transfer the value to the next layer, but before, multiplies its value by a factor Wxx, called weight. This is like a lineal regression, is a kind of slope.
- This next layer, called Hidden Layer, receives in each node the sum of Input Values x Weights.
- The main difference between Neural Net and other ML algorithm lies in the symbol inside the node, also represented by “f” letter: the Activation function. The activation function is a second transformation inside the node before transmit data to the next layer. We can choose an activation function(usually within a set of existing functions) and more commons are Sigmoid, REL, Hyperbolic tangent. Before train the model, we set this function.
- The model training process goal is getting weights values that minimize RMSE (cost, loss, difference between prediction and actual), as we do with lineal regression.
Note: I have made lots of simplifications, buy I don´t really care, I just intend to do a soft introduction to ML. Only one important concept: if we train iterations with a big set of training data, we are testing lots of values of weights. We must think that we have different weights to calculate, one per node connection and for complex systems this could be a madness if you do it without some optimization tool. There are mathematical tools to speed up the search of weight values, like Back Propagation or Gradient Descent.
Machine learning (ML)Tools.
There are a lot of people who do ML models with Phyton or JavaScript using their math libraries. Hat off for the braves, but I´m not going to follow their way.
These languages have ML libraries like Scikit or TensorFlow, with a lot of work done: algorithm implementations, data refinery utilities, RMSE calculation statements: if you have business and data science knowledge (no small achievement), code training model could be easy or almost easy.
One step beyond, the big companies, Microsoft or IBM have ML trainers in theirs cloud platforms.
Acknowledgements.
All the images but RMSE formula have been done by Alba Almaraz Anguiano, student of last year of tech high-school. Thank you very much, explain all these concepts without pictures could have been almost impossible for me.
*This post is locked for comments