However, sometimes you may also want to use this data in your own data warehouse technology or reporting architecture, so it may be required to create an integration to those systems.This article explores different options that are available within Fabric to achieve this. Depending on the concrete scenario and capabilities, different ways might be applicable.Prerequisites
To transport data from Fabric into some other destination, we need access the data from a Fabric lakehouse. The basic setup and how to create a workspace in Fabric is described in this article.Once the lakehouse is created, you could add shortcuts to the corresponding Dataverse tables. Use the “Get data” menu item or the context menu on the “Tables” node in the data explorer to create a new shortcut: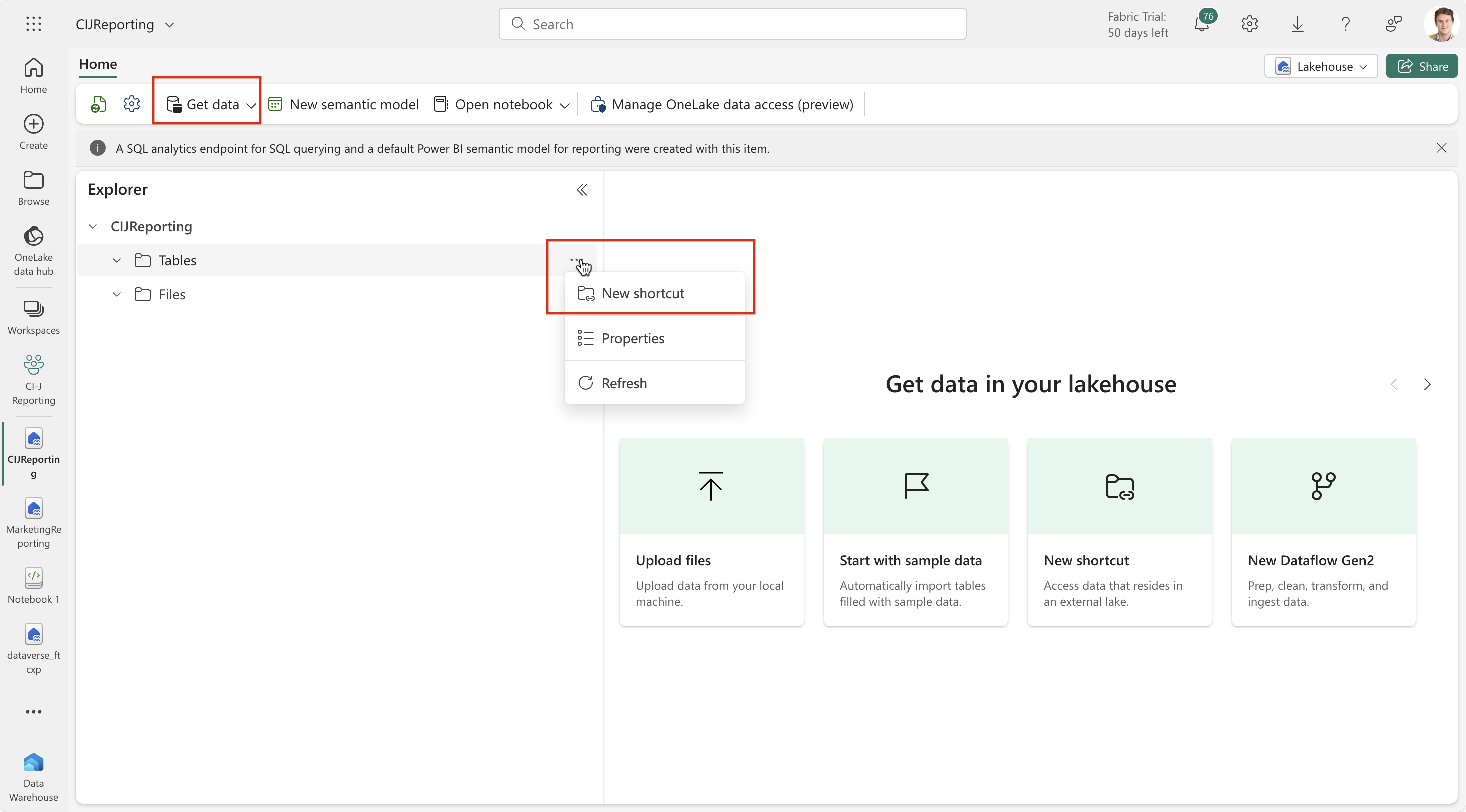
The next screen allows to select Dataverse as the source for shortcut:
Next, the connection to Dataverse needs to be entered. Select the CI-J environment from which you want to ingest the data. On the following screen, the tables must be selected for which the shortcuts should be created. The following directories are available from which only the first two entries “CDS2” and "Customer Insights - Journeys" are relevant:
Expand the directory tree on the left side to select multiple tables / entries. In my example, I checked all email related entries from the “Customer Insights Journeys” directory and “contact_partitioned” from the “CDS2” directory. Then next screen even allows you to rename the table shortcuts. “CDS2 > contact_partitioned” was renamed here to “Contacts”.
Pressing the “Create” button will create the shortcuts in the lakehouse:
At this point, also a SQL analytics endpoint is created that can be used to access this lakehouse data through a SQL endpoint. Depending on the way the data should be made available, different data transfer patterns might be used. The next section will explore the details about this.
Please note:Microsoft Fabric accesses the data in the CI-J environment through a link or shortcut. The general concept is shown in the following picture.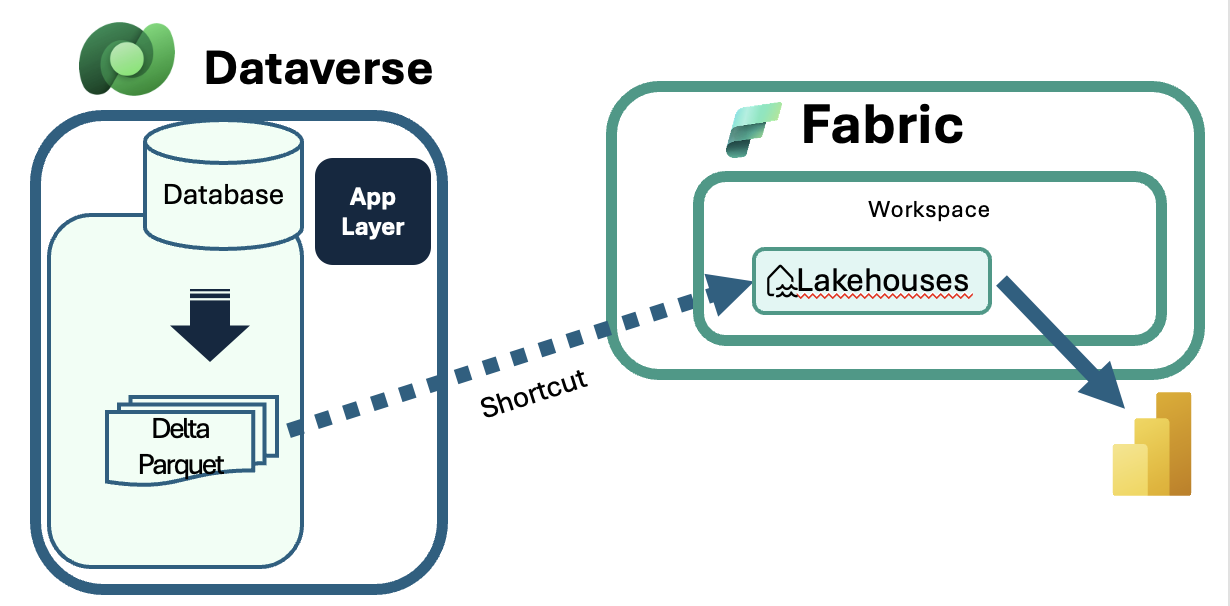
This means that no data is copied over from Dataverse to Fabric. Instead, the Fabric shortcut expects the data to be available in a data lake format. In a CI-J environment, the data lakes are created automatically in the “Customer Insights – Journeys” folder as soon as first journeys are running and interactions are captured. There are also additional tables in the “CDS2” folder for which data lakes are also created and which are typically needed for analytics dashboards, for example the “contact” entity.However, not all Dataverse tables have corresponding data lakes. If you want to link your full environment with all tables, follow the steps in this article on how to accomplish this. Please keep in mind that hereby, all Dataverse tables of the environment are taken into consideration which might have impact on your Dataverse capacity.
Patterns for data transfer
To transfer data from A to B, some sort of workflow engine or ETL tool is required. Typically, ETL tools (extract-transfer-load) are used for such purposes and data transfer can happen frequently or on demand. In general, there are two patterns to transfer data from A to B.- Pull: an external system has the capability to accesses MS Fabric, extract the data and store it somewhere else. In this case, the ETL capabilities are outside of MS Fabric and the SQL endpoint for the lakehouse can be used to access the data.
- Push: Fabric as the source system provides a data pump that pushes the data to some external system. Here, Fabric Data Factory pipelines can be used as the ETL tool to transfer the data.
If you don’t have an ETL tool at all, it is certainly a good idea to look into the functionality that is provided within Fabric itself.
Let’s look at some of the details for each of the patterns.
Pull data from Fabric
In some cases, organizations may already have an ETL tool in place that should be used for data transfer tasks. In such cases, Fabric provides a SQL endpoint for the lakehouse and the semantic model.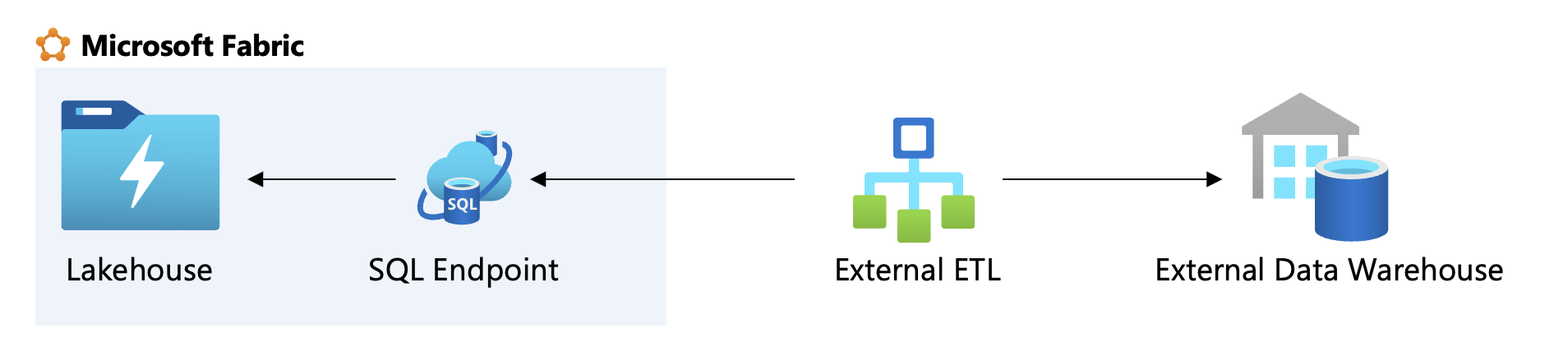
If you open your workspace, you can see the semantic model itself and the SQL analytics endpoint that has been created.
Clicking on this entry opens the following screen from which you can open the settings dialog.
Here, you can copy the SQL connection string and use it in your desired application and run queries. You can also use SQL Server Management Studio or Power Automate (use the Azure SQL Data Warehouse connector) etc. to access the data model and run queries.
The advantage of this approach is that you can use the fabric data right away if your ETL supports querying an SQL endpoint. For example, you could use SQL Server Integration Services to connect to Fabric through the SQL endpoint information and the Microsoft OLEDB provider.
You can use the Data Link Properties to define the connection and also its properties. Afterwards, Fabric is just another data source within SSIS and you can access, transform and load the data to another destination such as a local database.
Push data from Fabric to external destinations
Microsoft Fabric also contains a way to transfer data to external systems. For this purpose, Fabric Data Factory can be used to create a pipeline for the export. Data Factory is also available within Fabric to transfer data. An easy way to transfer data would be to use the “copy data” function which allows you to access the semantic model in the lakehouse and copy the data over to the destination of your choice. To start with this, create a new data pipeline and choose the “copy data assistant” as a starting point. This will bring up the assistant to connect to the lakehouse and a destination of your choice.
After choosing the right lakehouse, the assistant presents the tables that have been linked from Dataverse in an earlier stage and all other tables that have been created.
Next, you can choose between the different destinations. Click on the “view more” link to expand to the full list. For the purpose of this walkthrough, we use a simple Azure Blob storage to transfer the data to. Depending on the destination, you need to provide the connection details for the connection.
In the case of a file storage like Azure Blob, we need to provide additional information for the destination folder, file name suffix and compression.
 The data copy activity, which was created by the wizard, creates the list of tables as pipeline parameters and iterates through this array to execute a copy action. The wizard also chooses some random names for the variables and activities which you can change afterwards of course.
The data copy activity, which was created by the wizard, creates the list of tables as pipeline parameters and iterates through this array to execute a copy action. The wizard also chooses some random names for the variables and activities which you can change afterwards of course.Recommendations
Data extraction methods vary in compute capacity requirements. Just querying data from Fabric is usually cheaper than using tools like Data Factory or notebooks within Fabric to transfer data out of Fabric.Using the SQL endpoint for accessing data in a Fabric lakehouse is convenient but requires processing power, potentially causing performance issues if Fabric capacity is insufficient. Ensure you have adequate Fabric capacity for this option and the use case you want to address.While this article does not address capacity considerations, it is important to note that these factors may be pertinent to your specific scenario. Because it is hard to predict the required performance for a specific scenario, it is recommended to test out your specific scenario and use the telemetry tools to measure the utilization of the Fabric setup and adapt accordingly.Additionally, in both scenarios discussed in this article, you will receive the full dataset for interactions. To process only the changed data, you would need to adjust your queries according to the interval used for data extraction.Summary
Microsoft Fabric is a universal analytics and reporting platform that offers versatile capabilities for various data management needs. One of the key functionalities of Microsoft Fabric is the ability to export data, which is particularly useful for CI-J interaction data. By establishing a link to the managed datalake within Dataverse, users can leverage this feature without incurring additional storage or compute costs specifically for this use case.However, it is important to note that if you intend to utilize notebooks or other data processing tools within Microsoft Fabric, there may be additional costs associated with these activities.Moreover, Microsoft Fabric provides a seamless integration experience with Dataverse, ensuring that data updates are performed frequently. This frequent updating process facilitates easy usage and access to the most current data, enhancing the overall efficiency of data management tasks. By taking advantage of its integration with Dataverse and considering the potential costs of additional processing tools, users can maximize the benefits of this platform for their data management requirements.



