




 160
160 Like
Like Share
Share
 Report
ReportThe requirement
One of our customers asked us to develop an integration between their Dynamics 365 CRM and the PIM (Product Information Management) they use to manage their products. This way the products would be kept up-to-date daily. The PIM they use has a fairly easy way of exposing the products in a CSV file. All we need to do is configure which fields we want to display in this file and add some filtering to it. Then just call the endpoint they provide with it and it returns the CSV file with all the products we need to process.
Of course, our first thought was to tackle this with Power Automate. Just set up a scheduled Cloud Flow, call the endpoint and parse the products from the CSV file. This way we can create new, or update existing products within Dynamics 365 based on a unique identifier (product code).
But there was only one (major) problem. Power Automate does not provide a built-in way of processing CSV files. Only some premium (paid) connectors are available to us. And as we don’t want to make our customers pay more as they should, we started playing around with some of the standard functionalities Power Automate provides.
Set up the Cloud Flow
First of all, as mentioned before, the Cloud Flow will run daily. So for this we set up a scheduled Cloud Flow that runs every 24h. And the first thing it needs to do is call the endpoint the PIM provided to receive the CSV file we configured.
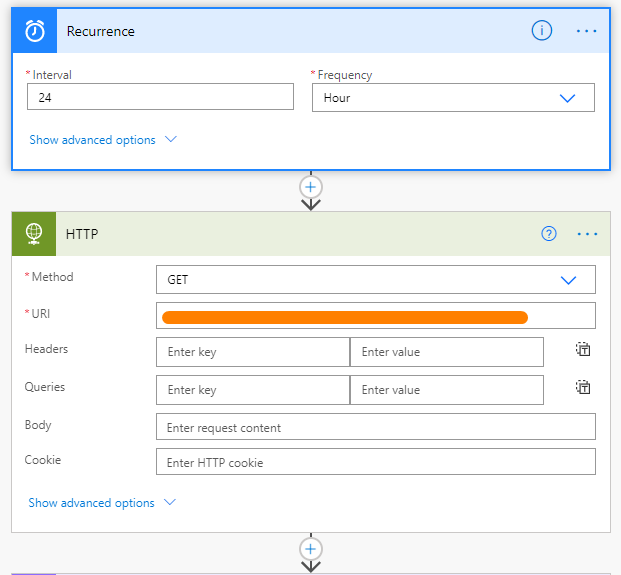
For the sake of this blog post and in order not to expose sensitive data coming directly from our customers, we will be using a local file retrieved from my OneDrive from now on. The markup of the file and the result in the end will be exactly the same as the real thing.
After a first test, we get plain text in the response like this:
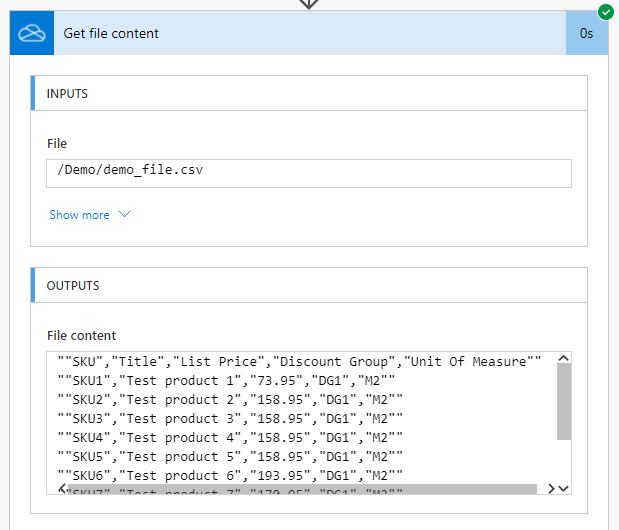
Of course, we can’t do much processing with flat text. We should be able to read every line separately to process it in a further stadium. Therefor we’re going to split these lines into an array. One line each making 1 entry in our newly formed array.
Compose, Compose, Compose
For this we select the “Compose” action from the built-in Data Operations.
Inside of this action we split the contents with following Expression:
split(outputs('Get_file_content')?['body'], decodeUriComponent('%0D%0A'))
But to get it right, we must first determine the kind of line ending our CSV file is using. In my case it’s CR LF. You can find this out yourself by opening the file in notepad and check the bottom of the screen.
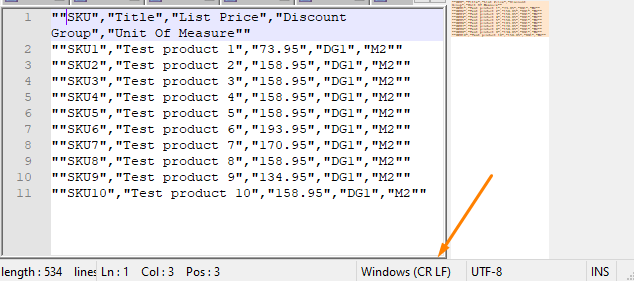
CR LF represents \r\n line endings so we need to use %0D%0A as the separator to get it right. In case you don’t know, these are just the encoded values of \r\n.
If it says LF, you will only need %0A.
When we give it a spin, we should get something like the following. An array of lines of text. Product lines in our case:

The next step is basically doing the same thing for each line of the array. But as you can see for the first line of our array, we still have the header of the CSV file in there. We won’t be needing this when we parse the products, so we need to skip the first line.
Inside an Apply to each we take the output of our previous Compose and skip the first line with following Expression:
skip(outputs('Split,_CSV_into_array'), 1)
Basically it just says, take the output, but skip the first line.

Then for each item of this output, (again) we take a Compose action, with a split into an array. This time we use “, as the separator. The double quotes are important not to forget. If we wouldn’t add them as part of the separator and one of our column values contains a comma, we wouldn’t get the output we expect!
Which leads us to following outcome:

I know, it does seem a bit off doesn’t it.. But we’ll get there! 
After that, we take yet another Compose to build our JSON object in plain text. With keys by choice and the values of our previous output like this:

Every line contains an Expression like
replace(outputs('Split_By_Comma')?[0], '"', '')
replace(outputs('Split_By_Comma')?[1], '"', '')
Since we composed each column as an array line, we can get to every parsed value by its index number (which is zero-indexed). As an example you can see I took the first and the second one. To replace the remaining double quotes we’ve read from our CSV file, we first surround the value with a replace expression. It will just replace all those double quotes with nothing instead.
This leads us to the following output, a valid JSON object which we can use for further processing inside of our Cloud Flow.

As we finally parse our csv data through our last action, the Parse JSON action from within Data Operations, we will have the keys and values of our custom built JSON object at our disposal. Of course you can use the nifty “Generate from sample” to generate the JSON scheme Power Automate needs to parse the keys and values.

So that’s about it! From here you will be able to use the JSON object as you would otherwise in Power Automate.
Thanks for reading!
If you need any help regarding Dynamics 365 customizations and/or configuration, feel free to contact us!
Het bericht Power Automate: Parse CSV files verscheen eerst op Thrives.
*This post is locked for comments